
1. Introduction: The Unseen Choreography of Global Code Collaboration
For the discerning eye of a senior engineer, a platform like GitHub transcends its familiar web interface and command-line interactions. It is not merely a service; it is a masterclass in distributed systems engineering, a testament to overcoming monumental challenges at an astonishing, planet-scale velocity. Every git push, every pull request review, every CI/CD trigger initiates a meticulously choreographed dance across a vast, interconnected fabric of compute, storage, and network infrastructure. This complex ballet, largely unseen by its millions of users, represents the pinnacle of modern software architecture.
This article endeavors to dissect the profound engineering challenges and the sophisticated architectural paradigms required to construct such a global code collaboration platform. We will move beyond superficial descriptions to explore the fundamental friction points that arise when attempting to unify Git’s inherently distributed nature with the stringent demands of a centralized, highly available hosting provider. Our focus will be on the non-obvious trade-offs, the elegant, often battle-hardened solutions, and the critical design decisions that underpin a system capable of seamlessly managing petabytes of code, orchestrating millions of concurrent developer interactions, and maintaining unwavering availability across every continent.
Our discussion is positioned at the crucial intersection of Git’s powerful distributed data model and the centralized operational reality of a hyperscale service. This unique tension introduces a myriad of complexities – from ensuring strong data consistency for critical metadata to managing the sheer volume and velocity of collaboration events. We will illuminate how these inherent friction points are not just addressed, but elegantly resolved through a suite of sophisticated architectural choices, providing a blueprint for engineers grappling with similar challenges in building their own resilient, high-performance distributed systems.
2. The Grand Problem Statement: Friction Points in Unifying Git at Scale
Building a planet-scale source control and collaboration fabric necessitates confronting a unique set of challenges that arise from the intersection of Git’s inherent design principles and the rigorous demands of a globally distributed, highly available service. This section deep-dives into these fundamental friction points.
2.1. Reconciling Distributed Git with Centralized Hosting Operational Demands
Git, at its philosophical core, is a local-first, peer-to-peer distributed version control system (DVCS). Every developer holds a complete copy of the repository’s history, enabling offline work, high resilience to network outages, and distributed workflows. This design is elegant for individual or small team collaboration. However, the paradigm shifts dramatically when attempting to provide a managed, centralized hosting service for millions of such repositories.
The inherent tension lies in bridging this philosophical gap. How does one leverage Git’s distributed advantages—its robustness, its content-addressable integrity, its efficient local operations—while simultaneously providing the non-negotiable guarantees of a centralized service: high availability, global replication, consistent security, and predictable performance?
- Statefulness vs. Statelessness: Git repositories, with their local object databases and mutable references (branches, tags), are inherently stateful entities. In contrast, hyperscale web services thrive on stateless application servers for horizontal scalability and resilience. Reconciling these two paradigms is a significant hurdle. Directly mounting local Git repositories to numerous application servers quickly becomes an operational nightmare due to locking, consistency issues, and the “noisy neighbor” problem.
- Individual vs. Aggregate Performance Optimization: A local Git repository is optimized for individual developer performance. A git clone or git push often involves intensive local CPU and I/O. At the scale of millions of repositories, optimizing for individual operations must not degrade aggregate system performance. This requires sophisticated resource management, fair scheduling, and intelligent caching strategies to prevent “thundering herd” problems or a small percentage of large operations from impacting the entire platform.
- Centralized Guarantees: Providing features like integrated web UIs, pull requests, issue tracking, and a unified security model (authentication, authorization) inherently requires a centralized source of truth for metadata and a consistent view of the Git graph, which contradicts Git’s distributed origin.
2.2. The Petabyte-Scale Repository & Object Graph Management
Beyond merely storing files, a platform like GitHub manages a vast, intricate content-addressable object graph. Git’s fundamental building blocks—blobs (file contents), trees (directory structures), commits (snapshots + metadata), and tags (pointers)—are all immutable, cryptographically hashed objects. References (branches, tags) are mutable pointers to these immutable objects. Scaling this architecture to petabytes of data across millions of repositories presents a unique set of challenges:
- Beyond Simple File Storage: This isn’t just about storing opaque blobs; it’s about understanding and optimizing access to an interconnected graph. Operations like git clone or git fetch involve traversing this graph, identifying new objects, and packing them efficiently, often requiring significant CPU and I/O resources.
- Diverse I/O Patterns: The system must efficiently handle:
- Small, Frequent Writes: Every git push potentially adds new commits, blobs, and trees, and critically, updates branch references. These need to be fast, atomic, and consistent.
- Large, Infrequent Reads: Initial git clone operations for large repositories can involve reading gigabytes of data. These operations are bursty and resource-intensive.
- Random Access Reads: Operations like git blame or viewing a specific file at an arbitrary commit require efficient random access into packed objects.
- Maintaining Referential Integrity: The core of Git’s power is its immutable history and cryptographic integrity. The hosting platform must guarantee that no object is lost, no history is rewritten accidentally (outside of explicit rebase/force push semantics), and all references correctly point to their intended objects, even amidst concurrent updates and distributed storage.
- Object Deduplication at Scale: Git inherently deduplicates objects within a repository. However, across millions of repositories, especially with frequent forks, efficient cross-repository object deduplication becomes a massive storage optimization opportunity, presenting significant computational and management overhead.
- Efficient Garbage Collection & Reachability: As old commits become unreachable (e.g., after force pushes or branch deletions), their objects eventually become candidates for garbage collection. Determining reachability across a graph of petabytes, safely and efficiently, without impacting live operations, is a non-trivial distributed systems problem.
2.3. The Real-time Interaction Conundrum: Event Causality & Fan-out
The “collaboration fabric” aspect of the platform is driven by a ceaseless torrent of events, far exceeding mere Git operations. Every user action or automated process generates data that needs to be processed, disseminated, and acted upon, often in real-time:
- Immense Event Volume and Velocity: From a new commit being pushed, a pull request being opened, a comment being posted, an issue being assigned, to webhooks firing, and CI/CD triggers activating—millions of these discrete events occur every second. The system must ingest this data without bottlenecks.
- Low-Latency Processing & Dissemination: Developers expect immediate feedback. A comment posted should appear instantly. A code push should trigger CI within seconds. This necessitates processing pipelines that are not only high-throughput but also low-latency.
- Guaranteed Delivery (At Least Once Semantics): For critical events (e.g., “new push to protected branch,” “security vulnerability reported”), messages cannot be lost. The system must guarantee that events are processed and delivered, even in the face of transient failures, often requiring robust retry mechanisms and persistent queues.
- Strict Event Ordering (Where Necessary): While many events can be processed concurrently, some interactions demand strict ordering. For instance, comments on a pull request should appear in the order they were submitted. Concurrent pushes to the same branch require careful sequencing to avoid conflicts or data loss. Ensuring this causality across a distributed system is incredibly complex.
- Massive Fan-out: A single event, like a new commit, might need to be fanned out to:
- Internal services (e.g., search indexers, notification services).
- The web UI (real-time updates).
- Email/Slack/other notification channels.
- Hundreds or thousands of external webhook subscribers (CI/CD, third-party integrations).
This “one-to-many” dissemination, coupled with varying subscriber reliability and rate limits, introduces significant challenges in managing delivery, retries, and backpressure.
- Maintaining Logical Consistency Across the Fabric: When an event occurs, its implications might span multiple independent services. A new push impacts the Git repository, the search index, notifications, and potentially CI systems. Ensuring that all these disparate components eventually reflect a consistent view of the world, especially when dealing with concurrent events, requires careful architectural design around eventual consistency.
2.4. Metadata Consistency & Transactional Guarantees for the Collaboration Plane
While Git itself manages code history with cryptographic integrity, the surrounding collaboration fabric requires an equally robust, yet fundamentally different, approach to data management. This core metadata layer governs the entire user experience and system functionality: who owns what, who can access what, the state of collaborative workflows, and the context of all interactions.
Requirements for Strong Consistency: Data pertaining to user accounts, organization structures, repository permissions, pull request states (e.g., “open,” “merged”), issue trackers, and comments demands strong consistency. A user must immediately see their comment after posting it, a permission change must take effect instantaneously, and a merged pull request must definitively reflect its final state. Deviations from this could lead to security vulnerabilities, data corruption, or a completely broken user experience. This necessitates a transactional data store capable of ACID (Atomicity, Consistency, Isolation, Durability) guarantees.
Scaling Transactional Relational Databases: The natural fit for such strongly consistent, highly relational data is a traditional RDBMS (e.g., PostgreSQL). However, scaling a single RDBMS instance to handle millions of queries per second (QPS) with continuous growth in data volume and concurrent connections is a monumental engineering feat.
Complex, Highly-Joined Queries: The collaboration features often involve complex queries that join across multiple tables—e.g., “show all open pull requests for this user across these organizations, filtered by labels and assigned to me.” Optimizing these queries for performance across a massive, sharded database is a continuous challenge.
The Cost of Distributed Transactions: As the system scales horizontally and data is sharded across multiple database instances, maintaining transactional integrity across these shards becomes exceptionally complex and expensive. Two-phase commit protocols or similar distributed transaction managers introduce significant latency and operational overhead, often at odds with hyperscale performance demands. This forces architects to carefully consider transaction boundaries and data locality.
CAP Theorem Implications for Critical Metadata: When scaling horizontally (partitioning), the CAP theorem dictates a choice between Consistency and Availability during network partitions. For critical metadata, Consistency is paramount. This often means sacrificing some availability during severe network partitions, or, more commonly, adopting sophisticated replication and failover strategies that minimize outage windows while preserving data integrity.
Challenges with Global Unique Constraints: Ensuring global uniqueness (e.g., username, repository URL) across a sharded, distributed database can be difficult. Simple auto-incrementing IDs become problematic. Solutions often involve UUIDs, distributed sequence generators, or dedicated coordination services, each with its own trade-offs in terms of complexity, performance, and collision probability. Managing concurrent modifications to globally unique resources is a primary source of distributed systems headaches.
2.5. Intelligent Code Discovery & Contextual Search
For a platform built on code, the ability to rapidly discover, navigate, and comprehend code is not a luxury, but a core feature. This goes far beyond basic substring matching; it demands an “intelligent” search capability aware of the underlying structure and semantics of programming languages.
Beyond Basic Full-Text Search: The challenge isn’t just indexing billions of lines of text; it’s about indexing code. This requires:
Semantic Awareness: Understanding language constructs, definitions, references, and relationships within the code. Searching for a function definition should distinguish it from its usage, or a variable declaration from its value.
Language-Specific Filters: Enabling users to filter by programming language, file extension, or even more granular language features.
Advanced Query Capabilities: Supporting powerful search operators, including regular expressions, fuzzy matching, and filtering by repository, organization, user, file path, and commit range.
Indexing Billions of Lines of Code: The sheer volume of code presents a massive indexing challenge. Each commit to a repository can potentially change hundreds or thousands of files, requiring incremental re-indexing.
The Unique Challenges of Tokenization and Analysis for Programming Languages: Standard text analyzers are insufficient. Code requires specialized tokenizers that understand keywords, identifiers, symbols, string literals, and comments. Syntax highlighting, for instance, implies a parsing step that can be leveraged for indexing.
Handling Massive Index Sizes and Distributed Query Execution: The resulting search indices can easily span petabytes. Distributing this index across a cluster of search nodes (e.g., Elasticsearch) and efficiently executing complex queries across these distributed shards, then aggregating results, is a significant architectural and operational undertaking.
Maintaining High Data Freshness & Low Query Latency: Developers expect code search results to be almost instantaneously updated after a git push. Achieving sub-second query latency for complex searches across a constantly evolving, massive corpus requires highly optimized indexing pipelines, efficient cluster management, aggressive caching, and smart query routing. This often means embracing eventual consistency for the search index, but striving for an extremely short latency to consistency.
Cost Optimization: The resource demands (CPU, memory, disk I/O) for indexing and querying at this scale are immense. Balancing performance and freshness with the cost of maintaining such a large, active search infrastructure is a continuous architectural concern.
3. Architectural Pillars: Engineering the Fabric’s Resilience and Performance
Having established the intricate problem space, we now pivot to the architectural pillars that form the bedrock of a planet-scale source control and collaboration fabric. These solutions are not merely implementations but strategic decisions forged by the crucible of scale and operational demand.
3.1. The Git Storage & Access Fabric: Decoupling and Scaling Core Operations
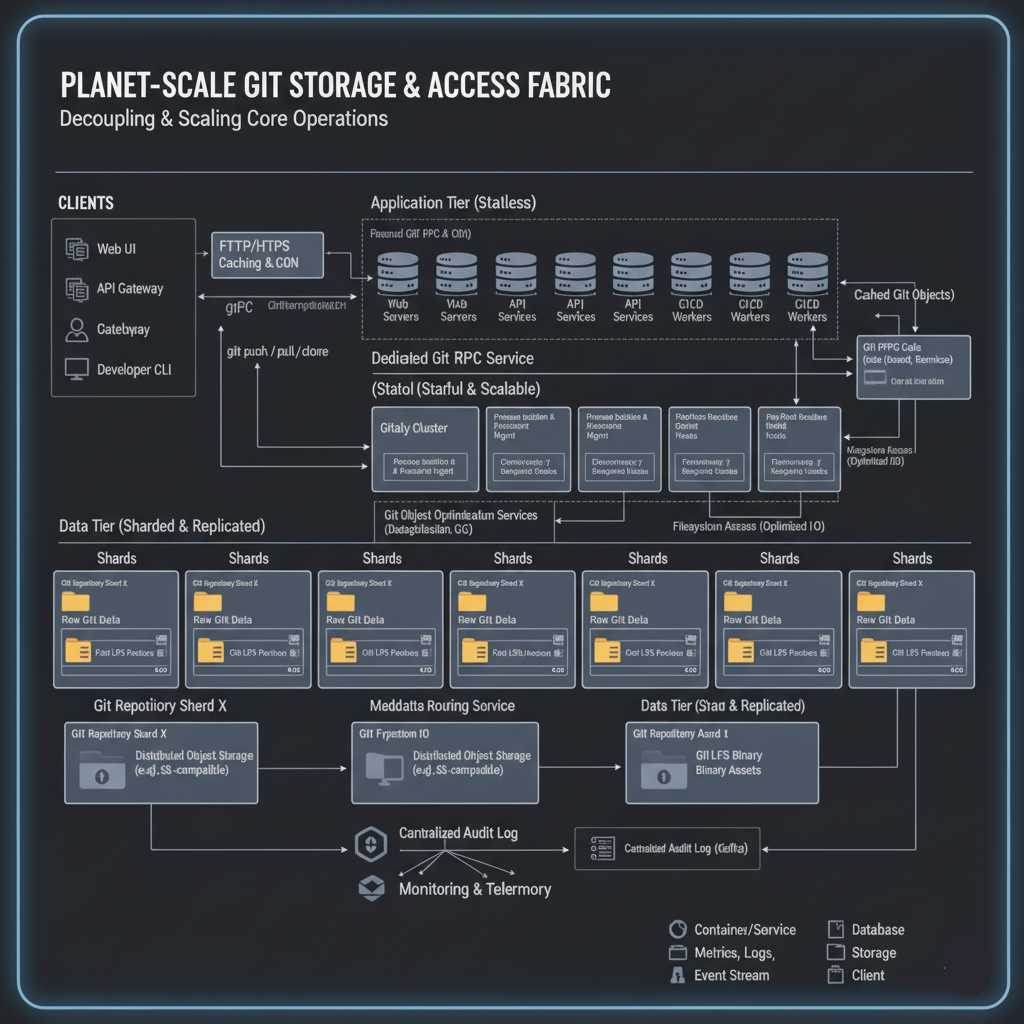
The fundamental challenge of hosting millions of Git repositories lies in harmonizing Git’s stateful, local-first nature with the stateless, horizontally scalable demands of a web service. The solution is a meticulously designed Git Storage & Access Fabric that decouples the concerns of raw Git data management from the application logic.
Core Solution: Sharded, Distributed Object Storage with a Dedicated Git RPC Layer (e.g., Gitaly Model)
At the heart of this pillar is a two-pronged strategy:
- Horizontal Sharding of Repositories: Millions of Git repositories are not stored on a single monolithic server, nor are they simply spread across a vast, undifferentiated file system. Instead, repositories are horizontally sharded across numerous purpose-built storage nodes. Each shard is responsible for a subset of repositories, physically storing their Git objects, refs, and other associated files. The mapping from a repository ID to its specific shard is managed by a routing layer (often a metadata service), allowing for efficient lookup and load distribution. This approach ensures that no single storage node becomes a bottleneck and enables incremental scaling.
- Dedicated Git RPC Service (e.g., Gitaly): This is the lynchpin. Application servers (web frontends, API services) do not directly interact with raw Git repositories on disk. Instead, all Git operations are proxied through a specialized, high-performance Git RPC service(exemplified by GitHub’s Gitaly). This service acts as a Git-native API gateway, abstracting the complexities of raw Git commands, managing the lifecycle of git processes, and providing a consistent, versioned gRPC interface for all Git interactions.
- Abstraction of Git Commands: Instead of application servers executing shell commands like git push or git rev-list, they invoke gRPC methods like ReceivePack or RefList on the Git RPC service.
- Process Isolation & Resource Management: Each Git operation often spawns a gitprocess. The RPC service manages these processes, isolating them from application servers, allocating resources efficiently, and preventing resource exhaustion from runaway Git processes.
- Concurrency Control for References: Git references (branches, tags) are mutable and critical. The RPC service implements sophisticated concurrency control mechanisms (e.g., using optimistic locking or compare-and-swap operations) to ensure atomic updates to references, preventing data corruption during concurrent pushes to the same branch.
- Pre/Post-Receive Hook Execution: The RPC layer is the logical place to execute pre-receive (e.g., enforce branch protection rules) and post-receive hooks (e.g., trigger CI/CD, send webhooks), centralizing this logic and ensuring its consistent application across all repositories.
- Git Object Optimization Services: This layer can also expose services for Git object deduplication (within a repository and potentially across forks), efficient packfile generation, and garbage collection, preventing application servers from needing to understand these low-level Git mechanics.
Benefits of this Architecture:
- Isolation of Git Complexity: Application servers become largely stateless regarding Git, focusing solely on application logic. All the intricate, stateful, and often CPU-bound Git logic is encapsulated within the Git RPC service.
- Independent Scaling: The Git storage nodes/RPC services can be scaled independently of the web/API application servers. If Git operations are particularly heavy, only the Git infrastructure needs to be scaled up, not the entire application stack.
- Consistent, Versioned API: Provides a stable and evolvable API for Git interactions, simplifying client development and maintenance.
- Robust Error Handling & Fault Isolation: Failures or resource exhaustion within a Git process are contained within the RPC service, preventing cascading failures to the broader application. Robust error reporting and retry mechanisms can be built directly into the RPC layer.
- Enhanced Security through Process Isolation: Separating the execution of Git commands into dedicated, sandboxed environments on the RPC servers reduces the attack surface on the main application servers.
Architectural Trade-offs & Alternatives Analysis:
- Why not direct NFS/SAN mounts to application servers?
- Limitations: While seemingly simple, this approach fails catastrophically at scale. NFS/SAN introduces significant latency as network I/O becomes a bottleneck. It creates single points of failure (the NFS server itself or the network path). It struggles with scalability bottlenecks as shared file systems are notoriously difficult to scale horizontally while maintaining consistent performance. Furthermore, it’s inherently not cloud-native, requiring complex management of network-attached storage in a dynamic, elastic environment. Most critically, complex state management arises: multiple application instances trying to concurrently write to the same Git repository on a shared filesystem lead to race conditions, file locking issues, and data corruption without extremely sophisticated (and slow) coordination.
- Why not a pure blob storage + application-level Git logic?
- Immense Complexity: Attempting to replicate Git’s rich graph logic, atomicity, locking mechanisms, concurrent reference updates, and performance optimizations (like delta compression for packfiles) purely at the application layer is an Herculean task. Git is a highly optimized C program; reimplementing its core logic correctly and performantly in a general-purpose language, while also managing its object database on a generic blob store, would lead to an incredibly complex, slow, and error-prone application. The Git RPC service allows leveraging the battle-tested git binaries while providing a controlled, API-driven access layer.
Key Techniques within the Git Storage & Access Fabric:
- Git Packfile Optimization (Inter-Pack Delta Compression): Git stores objects in highly efficient packfiles, which use delta compression to store differences between similar objects. Advanced strategies involve re-packing repositories periodically to optimize these deltas across multiple packfiles (inter-pack delta compression) to minimize storage footprint and improve fetch performance.
- “Alternates” for Efficient Forking (Shared Object Databases): When a repository is forked, much of its history is identical to the upstream. Git’s “alternates” mechanism allows a repository to reference objects from another repository’s object database. This dramatically reduces storage needs for forks, as they only need to store their unique objects, sharing the common history with the upstream. Managing these references at scale, especially during upstream changes, is handled by the Git RPC layer.
- Git LFS Integration for Large Binary Assets: For large binary files (images, videos, compiled artifacts) that would bloat Git repositories and degrade performance, Git Large File Storage (LFS) is crucial. Instead of storing the binary directly in Git, LFS stores small “pointer files” in the Git repository, while the actual binary content resides in dedicated distributed object storage (e.g., S3-compatible storage). The Git RPC service understands LFS and proxies these requests to the appropriate LFS backend, ensuring transparent handling for developers.
3.2. The Asynchronous Event Stream: Orchestrating Real-time Collaboration
The pulse of any collaboration platform is its event stream. Every user action, every state change, must be reliably communicated to various parts of the system and external integrations. Direct synchronous calls between services quickly become a bottleneck and a source of cascading failures. The solution lies in a robust, asynchronous, event-driven architecture.
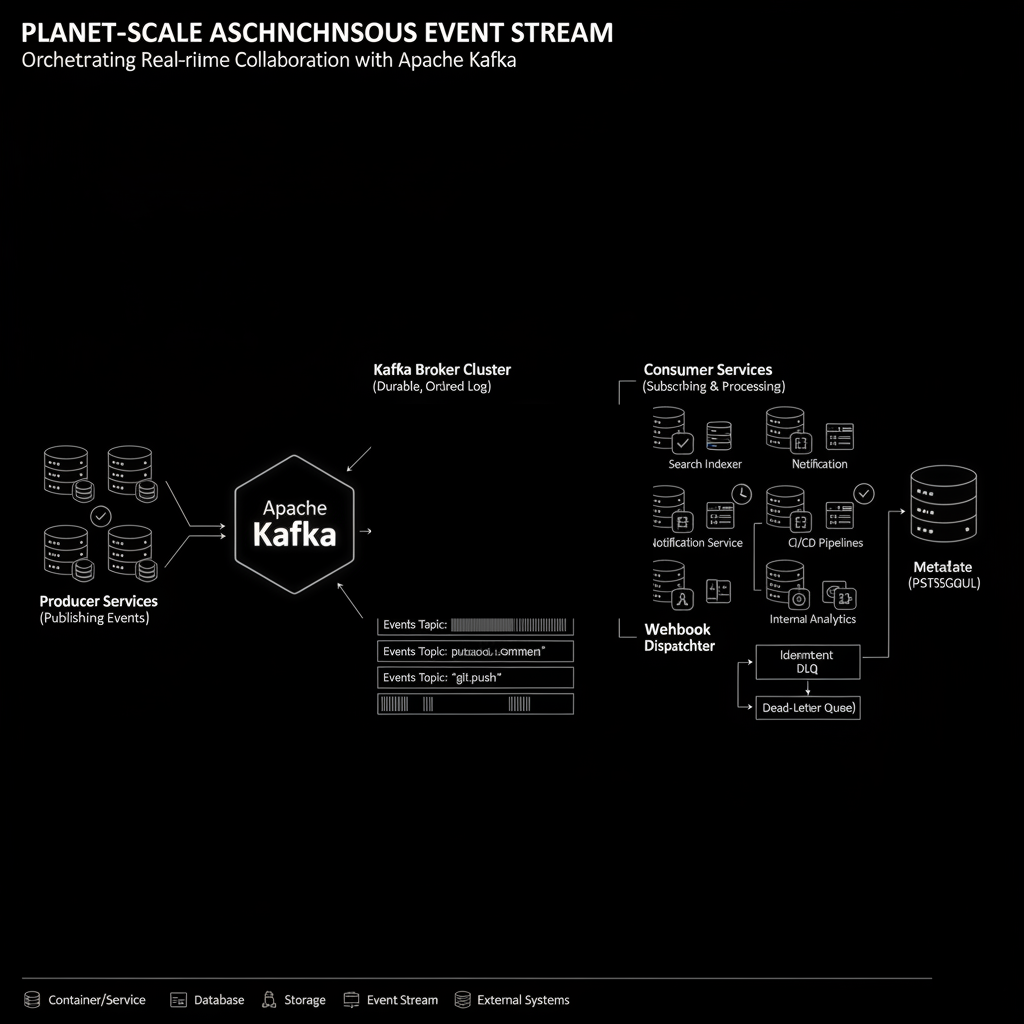
Core Solution: High-Throughput Distributed Log (e.g., Apache Kafka Cluster)
At the core of the collaboration fabric is a high-throughput, durable, and ordered distributed log, typically implemented using technologies like Apache Kafka. Every significant state change within the system—from a git push completing, a pull request being opened or merged, an issue being commented upon, to a webhook being triggered—is published as an immutable event to a specific topic within this Kafka cluster.
- Central Event Backbone: Kafka effectively becomes the central nervous system of the entire platform. Services act as producers (publishing events) and consumers (subscribing to events), creating a highly decoupled ecosystem.
- Immutability and Ordering: Events are appended to topics as an immutable, ordered sequence within a partition. This provides a clear, auditable history of all state changes, crucial for debugging, auditing, and ensuring consistent processing.
- Durability and High Availability: Kafka is designed for high durability, persisting events to disk and replicating them across multiple brokers. This ensures that events are not lost even in the face of broker failures, contributing to the overall fault tolerance of the system.
Benefits of this Architecture:
- Decoupling Producers from Consumers: Services can operate independently. A service publishing an event doesn’t need to know who (or how many) will consume it. This improves modularity, reduces inter-service dependencies, and simplifies deployment.
- Enabling Eventual Consistency Patterns: Many services can consume the same event stream to build their own derived state. For instance, a git push event can be consumed by the Git RPC service (to update references), the search indexer (to re-index files), the notification service (to alert users), and the CI/CD pipeline. Each service processes the event at its own pace, leading to an eventually consistent view of the system.
- Facilitating Massive Fan-out to Diverse Services: A single event can trigger actions across numerous internal microservices and external webhooks. Kafka’s consumer group model efficiently handles this fan-out, allowing multiple distinct services or instances to consume the same stream independently without contention.
- Robust Foundation for Auditing, Stream Processing, and Event Replay: The durable, ordered log serves as a perfect audit trail. It enables real-time stream processing for analytics, anomaly detection, or complex event correlation. Critically, it allows for event replay—reprocessing historical events—which is invaluable for disaster recovery, building new features, or backfilling data into new services.
- High Durability and Fault Tolerance: Kafka’s distributed nature, replication, and persistent storage ensure that the event stream itself is highly resilient to failures, minimizing data loss and downtime.
Architectural Trade-offs & Alternatives Analysis:
- Why not direct synchronous API calls between services?
- Limitations:
- Tight Coupling: Services become tightly coupled, making independent development and deployment difficult.
- Synchronous Cascade Failures: A failure in one downstream service can directly impact the upstream caller, leading to cascading outages across the system.
- Lack of Durability: If a downstream service is temporarily unavailable, the event is typically lost or requires complex retry logic in the caller.
- Scalability Bottlenecks: The caller’s throughput is limited by the slowest downstream service, making it hard to scale individual components.
- Limitations:
- Why Kafka over traditional Message Queues (e.g., RabbitMQ, SQS, Azure Service Bus, GCP Pub/Sub)?
- Emphasis on Kafka’s Unique Properties: While traditional message queues offer similar benefits like decoupling and asynchronicity, Kafka excels in specific areas crucial for a core, high-volume event bus:
- High Throughput for Sequential Reads/Writes: Kafka is optimized for high-volume, sequential appends and reads, making it ideal for continuous streams of events.
- Persistent, Ordered Log: Unlike many traditional queues that delete messages after consumption, Kafka retains messages for a configurable period, enabling event replay and multiple consumers to read the same history. This log-centric model is fundamental.
- Consumer Group Model: Kafka’s consumer groups allow multiple instances of a service to collectively consume a topic’s partitions in a load-balanced and fault-tolerant manner, ensuring messages are processed exactly once within the group. This is distinct from competing consumers where a message is consumed by only one worker.
- Scalability as a Distributed System: Kafka is designed as a distributed system from the ground up, allowing horizontal scaling of brokers and partitions to handle immense data volumes and client connections. While cloud-managed services (SQS, Pub/Sub) offer scalability, Kafka’s raw performance and control over ordering guarantees within partitions are often critical for the backbone.
- Emphasis on Kafka’s Unique Properties: While traditional message queues offer similar benefits like decoupling and asynchronicity, Kafka excels in specific areas crucial for a core, high-volume event bus:
Key Techniques within the Asynchronous Event Stream:
- Idempotent Consumers for Robust Retry Logic: Consumers are designed to produce the same outcome if processed multiple times. This is vital because “at least once” delivery is common in distributed logs. If a consumer fails and retries, idempotency prevents duplicate side effects (e.g., re-triggering a webhook, duplicating a database entry).
- Consumer Group Management for Load Balancing: Kafka consumer groups enable multiple instances of a consuming service to coordinate, ensuring that each message is processed by exactly one instance within the group, and partitions are dynamically rebalanced if instances join or leave.
- Dead-Letter Queues (DLQs) for Unprocessable Messages: Events that repeatedly fail processing (e.g., due to malformed data, external service unavailability) are routed to a DLQ. This prevents them from blocking the main processing pipeline and allows for manual inspection and remediation.
- Ensuring Effective “Exactly-Once” Processing Semantics: While true “exactly-once” delivery in a distributed system is incredibly hard, Kafka, combined with idempotent consumers and transactional producers/consumers, can achieve effective exactly-once semantics for many use cases, crucial for maintaining data integrity across downstream systems.
3.3. Metadata Persistence: The Strongly Consistent Relational Core
While eventual consistency is suitable for many parts of the collaboration fabric, the platform’s core metadata demands strong consistency and transactional guarantees. This data—defining users, organizations, repository permissions, and the definitive states of collaboration artifacts like pull requests and issues—forms the very backbone of the system’s integrity and security.
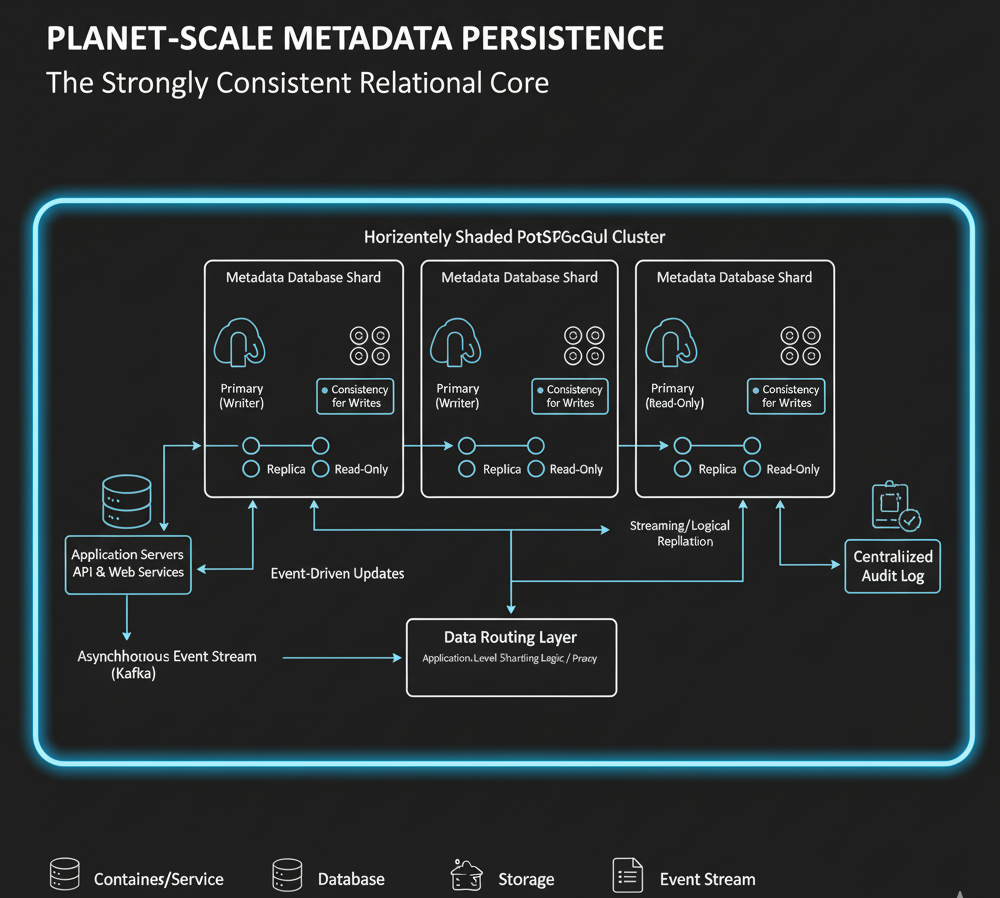
Core Solution: Horizontally Sharded, Replicated PostgreSQL Cluster (or equivalent RDBMS)
For this critical metadata, a robust Relational Database Management System (RDBMS), such as PostgreSQL, remains the optimal choice due to its ACID properties, mature ecosystem, and powerful querying capabilities. However, a single RDBMS instance cannot possibly handle the scale of a planet-wide collaboration platform. The solution involves:
- Horizontal Sharding: The metadata is horizontally partitioned (sharded) across numerous PostgreSQL instances. Sharding keys are carefully chosen—often based on stable identifiers like organization_id or repository_id—to distribute the data and query load evenly. This approach allows the database layer to scale out, rather than up, overcoming the inherent limitations of a single server. A dedicated routing layer or application-level logic determines which shard holds the data for a given request.
- Primary-Replica Replication: Each shard is typically configured with a primary database and one or more synchronous or asynchronous replicas. This provides high availability (failover from primary to replica) and allows for scaling read-heavy workloads by directing read queries to the replicas, offloading the primary.
- Strong Consistency for Writes: All write operations for a given shard are directed to its primary instance, ensuring strong consistency for critical state changes. Reads against the primary also offer strong consistency, while reads against replicas might be eventually consistent, depending on the replication lag.
Benefits of this Architecture:
- ACID Guarantees: Ensures atomicity, consistency, isolation, and durability for all critical metadata transactions, preventing data corruption and maintaining logical integrity.
- Complex Query Support: SQL provides a powerful and flexible language for expressing complex relationships and queries across the rich metadata graph (e.g., retrieving all pull requests for a given user across multiple organizations, filtered by status and labels).
- Mature Ecosystem: RDBMS platforms benefit from decades of development, offering robust tooling for monitoring, backup/restore, replication, and performance optimization.
- Scalability for Read-Heavy Workloads: Read replicas significantly increase read throughput and provide geographic locality for read operations.
- High Availability: Redundancy through replication ensures that service remains available even if a primary database instance fails.
Architectural Trade-offs & Alternatives Analysis:
- Why not a purely NoSQL approach (e.g., Key-Value, Document Stores)?
- Limitations: While NoSQL databases excel at horizontal scalability and high throughput for specific access patterns, they generally struggle with:
- Highly Interconnected Relational Data: GitHub’s metadata often involves complex relationships between entities (users to organizations, organizations to repositories, repositories to pull requests/issues). Performing complex joins across these entities is either inefficient or impossible in most NoSQL models without significant application-level code that effectively reimplements relational logic.
- Transactional Integrity: Many NoSQL databases offer weaker consistency models (eventual consistency) and lack robust support for multi-document or multi-collection transactions, which are critical for maintaining the integrity of core collaboration workflows (e.g., atomically creating a new repository and setting its permissions). While some (like MongoDB) have introduced transactions, they often come with performance caveats at scale.
- Data Modeling Complexity: Without a schema, ensuring consistency in data structures across a large, evolving codebase can become a challenge.
- Where NoSQL might be used: NoSQL databases could be effectively used for less critical, highly denormalized data (e.g., user activity feeds, ephemeral notifications, caches) where eventual consistency is acceptable and the query patterns are simpler (e.g., key-value lookups).
- Limitations: While NoSQL databases excel at horizontal scalability and high throughput for specific access patterns, they generally struggle with:
- Challenges Introduced by Sharding:
- Application-Level Sharding Logic: The application layer must be aware of the sharding scheme to correctly route queries and writes to the appropriate database shard, increasing application complexity.
- Joins Across Shards: Performing joins between tables that reside on different shards is notoriously difficult and inefficient. This forces data denormalization or complex application-level joining logic, often pushing aggregation to caching layers or batch processing.
- Global Transactions: Achieving ACID guarantees across multiple shards is a “distributed transaction” problem, typically requiring expensive two-phase commit protocols or complex compensatory transactions, significantly impacting performance and complicating error handling. This is usually avoided by carefully designing transaction boundaries to reside within a single shard where possible.
- Schema Evolution and Rebalancing: Evolving the database schema and rebalancing data across shards (e.g., when adding new shards or hot shards emerge) are complex operational tasks that require careful planning and tooling to perform without downtime.
Key Techniques within Metadata Persistence:
- Application-Level Sharding: Logic within the application code (or a dedicated proxy layer) determines the correct database shard for each operation based on the entity’s ID.
- Read Replicas: Utilizing streaming or logical replication to provide multiple read-only copies of the primary database. These replicas can serve geographically distributed read traffic and act as failover candidates.
- Connection Pooling: Efficiently managing database connections to minimize overhead and improve throughput, especially under high concurrency.
- Careful Index Design: Extensive use of appropriate indexes (B-tree, hash, GIN/GiST) is crucial for optimizing query performance on large tables.
- Query Optimization: Continuous profiling and optimization of SQL queries to ensure they scale efficiently with growing data volumes.
3.4. Intelligent Code Search & Discovery: Real-time Inverted Indices
For a platform where code is the primary asset, the ability to quickly and intelligently search through billions of lines of code, issues, and discussions is paramount. This capability transcends simple string matching, requiring a deep understanding of code structure and collaboration context.
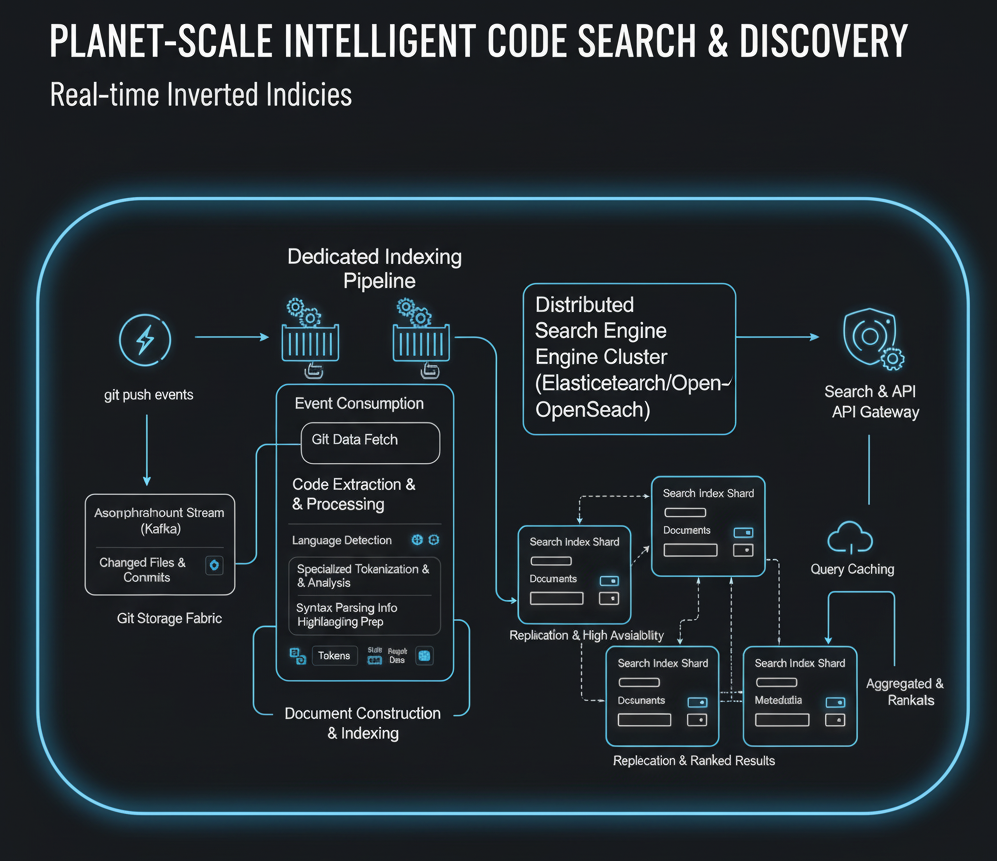
Core Solution: Distributed Search Engine Cluster (e.g., Elasticsearch/OpenSearch) with a Dedicated Indexing Pipeline
The solution for intelligent code discovery relies on a distributed search engine cluster(such as Elasticsearch or OpenSearch) combined with a highly efficient and purpose-built indexing pipeline.
- Distributed Search Engine Cluster: This cluster stores vast inverted indices that map terms (tokens derived from code) to the documents (code files, issues, pull requests) containing them. The cluster is horizontally scalable, with data partitioned across multiple nodes, offering fault tolerance and high query throughput. It supports sophisticated full-text search capabilities, complex query DSLs, and aggregation features.
- Dedicated Indexing Pipeline: This pipeline is a critical component that bridges the gap between raw Git data and the optimized search index.
- Event Consumption: It continuously consumes Git-related events (e.g., git pushcompletion) from the Asynchronous Event Stream (Kafka).
- Code Extraction and Processing: Upon a new push, the pipeline identifies changed files, fetches their content from the Git Storage Fabric, and performs extensive processing:
- Language Detection: Identifies the programming language of each file.
- Specialized Tokenization & Analysis: Unlike natural language, code requires custom analyzers. This involves tokenizing keywords, identifiers, symbols, operators, string literals, and comments. It might also involve syntax-aware parsing to extract semantic information (e.g., function names, class definitions, variable usages) for richer search queries.
- Syntax Highlighting Prep: The same parsing steps can be leveraged to generate pre-computed syntax highlighting data, improving UI performance.
- Document Construction & Indexing: Processed code and metadata (repository, author, commit info) are transformed into documents and pushed to the Elasticsearch/OpenSearch cluster for indexing.
Benefits of this Architecture:
- Scalable Full-Text Search: Designed from the ground up to handle massive datasets and high query loads, providing near-instantaneous search results across petabytes of code.
- Powerful Query Capabilities: Supports advanced features essential for code search:
- Language-Specific Filters: Searching only within Java, Python, or TypeScript.
- Regex Queries: Powering highly specific pattern matching within code.
- Structural Search: Beyond simple text, enabling queries that understand code constructs.
- Fuzzy Matching & Auto-completion: Improving developer experience.
- High Availability and Fault Tolerance: Search clusters are inherently distributed and replicated, ensuring that search capabilities remain available even if some nodes fail.
- Flexible Schema: Allows for evolving the search schema to incorporate new features or improve relevance without impacting the core data store.
Architectural Trade-offs & Alternatives Analysis:
- Why not relational database full-text search?
- Limitations: While RDBMS platforms offer basic full-text search capabilities (e.g., PostgreSQL’s tsvector), they generally fall short for planet-scale code search due to:
- Limited Scalability: Full-text search on a sharded RDBMS is challenging to scale horizontally, especially for complex, resource-intensive queries across vast datasets.
- Performance for Complex Queries: RDBMS full-text capabilities often lack the performance, advanced query syntax, and relevance tuning of dedicated search engines, particularly for code.
- Operational Overhead: Managing full-text indices alongside transactional data introduces contention and complicates database operations.
- Limitations: While RDBMS platforms offer basic full-text search capabilities (e.g., PostgreSQL’s tsvector), they generally fall short for planet-scale code search due to:
- Why not build a custom search engine from scratch?
- Immense Engineering Overhead: Building a distributed, fault-tolerant, high-performance search engine is an incredibly complex undertaking (consider the engineering effort behind Lucene/Elasticsearch). It involves challenges in distributed indexing, query parsing, relevance scoring, replication, and cluster management.
- Difficulty Matching Feature Set & Scalability: Custom solutions would struggle to match the rich feature set, battle-tested robustness, and operational maturity of established search engine technologies. The focus should be on building the integration and indexing pipeline, not reinventing the core search engine.
Key Techniques within Intelligent Code Discovery:
- Sharding the Index: Index data is typically sharded by repository or organization across the search cluster to distribute load and optimize query performance.
- Custom Language-Specific Analyzers and Tokenizers: Essential for correctly parsing and indexing programming languages (e.g., distinguishing function keyword from a variable named function).
- Efficient Incremental Indexing Strategies: Only re-indexing changed files or code segments after a git push to minimize indexing load and maintain data freshness. This relies heavily on the event stream and Git’s object model to identify changes efficiently.
- Caching Query Results: Aggressive caching of frequently executed search queries at various layers (CDN, API gateways, in-memory caches) to reduce load on the search cluster and improve latency.
- Distributed Query Execution: Breaking down complex user queries into sub-queries that run in parallel across multiple shards, then aggregating and ranking the results.
- Managing Large Index Sizes: Strategies for optimizing storage (e.g., using block-level compression, efficient data structures) and handling the massive memory and disk requirements of a petabyte-scale index.
- Ranking Algorithms: Developing sophisticated ranking algorithms that consider code relevance, repository popularity, file type, and other contextual factors to deliver the most useful results.
4. Cross-Cutting Concerns: Forging a Resilient and Developer-Centric Fabric
Beyond the core data and processing pillars, a planet-scale collaboration fabric relies on a set of critical, cross-cutting concerns that dictate its global reach, security posture, operational stability, and internal engineering velocity. These aren’t features; they are foundational requirements that permeate every architectural decision.
4.1. Global Distribution & Edge Computing: Mitigating the Speed of Light
The immutable laws of physics dictate that latency is directly proportional to distance. For a global developer audience, reducing network latency is paramount for user experience and Git operation performance.
Deep Dive:
- Content Delivery Networks (CDNs) for Static Assets and Strategic Git Objects: CDNs are not just for JavaScript and CSS. For a platform like this, they are strategically leveraged:
- Static Web Assets: Standard usage for HTML, CSS, JavaScript, images, etc., caching them close to the end-user.
- Cached Git Objects (e.g., Packfiles): More advanced CDN integration involves caching frequently accessed, immutable Git objects, particularly large packfiles resulting from popular repository clones. When a user requests a git clone or git fetch, the CDN can serve a significant portion of the objects from a nearby edge node, drastically reducing the load on origin servers and minimizing perceived latency. This requires intelligent CDN configuration to handle Git-specific HTTP protocol interactions and potentially custom cache invalidation strategies when new pushes occur.
- Multi-Region Service Deployments: Core services (web frontends, API gateways, and crucially, Git RPC services) are deployed in multiple, geographically distributed data centers or cloud regions. This brings computation and data access points closer to users, minimizing round-trip times for API calls and Git operations that cannot be fully cached at the edge.
- DNS-based Routing & Anycast: Advanced DNS services (e.g., Anycast DNS) are used to intelligently route client requests (both HTTP and Git protocol) to the closest healthy data center. This ensures optimal routing and also provides a critical layer for traffic shifting during regional outages.
Decision Points in Global Distribution:
- When to Replicate vs. Shard Data Geographically:
- Replication: For data where strong global consistency is less critical, or where reads are far more frequent than writes, data can be replicated across regions. This improves read latency and provides regional fault tolerance (e.g., database read replicas). However, managing cross-region replication lag and potential write conflicts requires careful design.
- Sharding: For data that demands strong consistency for writes or has high write volume, horizontal sharding is often employed within a region, and then these regional shards are potentially aggregated or federated globally. Global sharding (where shards are physically located in different regions) is extremely complex for strongly consistent data due to distributed transaction costs, but it can be necessary for extreme scale or data sovereignty requirements.
- Eventually Consistent Data: Most event streams and derived data (like search indices) are designed for eventual consistency, allowing them to be replicated or rebuilt regionally with acceptable latency, favoring availability and performance over immediate consistency across geographies.
- Challenges of Maintaining Eventual Consistency Across Regions: While embracing eventual consistency simplifies distributed data management, it introduces complexities. Services must be designed to tolerate temporary inconsistencies, resolve conflicts (e.g., using Last Write Wins, or more sophisticated CRDTs), and ensure that all replicas eventually converge to the same state. Monitoring replication lag and consistency drift becomes a critical operational concern.
4.2. Security & Authorization: The Policy Enforcement Matrix
In a platform managing sensitive intellectual property and collaborative workflows, an ironclad security and authorization model is non-negotiable. This goes beyond simple password protection; it’s a deeply integrated “Policy Enforcement Matrix” that governs every interaction.
Deep Dive:
- Granular Role-Based Access Control (RBAC): The core of authorization is a sophisticated RBAC system. Permissions are not assigned directly to users but to roles, which are then assigned to users or teams within specific scopes (e.g., repository, organization, enterprise). This allows for fine-grained control:
- Repository Permissions: Read, write, admin, merge, triage, etc.
- Organization Roles: Member, owner, billing manager.
- Team Permissions: Inheritance and override mechanisms for team-level access to repositories.
- Enterprise-level Policies: For large organizations, defining overarching policies that govern repository creation, visibility, and external collaboration.
- Integration with Enterprise Identity Providers (SAML, OAuth): Robust authentication extends beyond username/password. Integration with enterprise identity solutions (e.g., SAML, OAuth2, OpenID Connect) is crucial for large organizations to leverage their existing identity management systems, enforce corporate security policies, and enable single sign-on (SSO) and multi-factor authentication (MFA).
- Architecture of Policy Enforcement Points (PEP) and Policy Decision Points (PDP):
- Policy Enforcement Points (PEPs): These are embedded within every service (API gateway, web application, Git RPC service) where an access decision needs to be made. Before allowing an action (e.g., a git push, a POST request to an API, viewing a private file), the PEP intercepts the request.
- Policy Decision Points (PDPs): The PEP delegates the actual decision to a PDP, which is often a dedicated microservice. The PDP, querying the authoritative metadata store (e.g., the sharded PostgreSQL cluster) for user, organization, and repository permissions, evaluates the request against the relevant policies and returns an “Allow” or “Deny” decision.
- Caching & Performance: To minimize latency, PEPs often aggressively cache PDP decisions and user/role permissions, invalidating them rapidly on changes.
- Centralized Audit Logging of All Access Decisions: Every access attempt, whether successful or denied, is meticulously logged to an immutable audit trail (often leveraging the Asynchronous Event Stream). This is critical for security forensics, compliance, and detecting anomalous behavior.
Specifics:
- Least Privilege Principles: The entire system is designed around the principle of least privilege. Users and services are granted only the minimum permissions necessary to perform their functions.
- Secure by Design: All components are built with security in mind, incorporating practices like input validation, secure credential management, rate limiting, and protection against common web vulnerabilities (OWASP Top 10).
- Regular Security Audits and Penetration Testing: Continuous external and internal security assessments are vital to identify and remediate vulnerabilities.
4.3. Observability & Incident Management: Illuminating the Fabric’s Health
A distributed system as complex as this operates like a living organism. Understanding its health, diagnosing issues, and responding to incidents requires a comprehensive and highly granular observability stack.
Deep Dive:
- Comprehensive, High-Granularity Telemetry:
- Metrics: Thousands (or millions) of metrics collected from every service instance, database, and infrastructure component (CPU, memory, I/O, network, request rates, error rates, latency percentiles). Time-series databases (e.g., Prometheus, M3DB) are used for storage and querying.
- Structured Logs: Every service generates structured logs (e.g., JSON) capturing detailed information about requests, errors, and system events. These are aggregated into a centralized logging platform (e.g., Elasticsearch/Loki/Splunk) for searching and analysis.
- Distributed Traces: For complex, multi-service requests, distributed tracing (e.g., OpenTelemetry, Jaeger) is indispensable. It links individual operations across different services and processes, allowing engineers to visualize the full request path, identify bottlenecks, and pinpoint points of failure across the entire fabric. This is critical for debugging performance issues in a microservices environment.
- Sophisticated Alerting Systems: Automated alerting triggers based on predefined thresholds and anomaly detection rules across various metrics. Alerts are routed to on-call engineers via robust paging systems (e.g., PagerDuty), categorized by severity, and accompanied by relevant context (links to dashboards, runbooks).
- Automated Runbooks: For common issues, automated or semi-automated runbooks guide engineers through diagnostic steps and remediation actions, reducing mean time to recovery (MTTR).
- Robust Incident Response Framework: A well-defined incident management process, including roles (Incident Commander, Communications Lead, Scribe), communication protocols, and post-incident reviews (blameless post-mortems), is crucial for learning from failures and continuously improving reliability.
Specifics:
- Cardinality Challenges for Metrics: Managing metrics for millions of unique entities (repositories, users, API endpoints) creates high cardinality, which can overwhelm traditional monitoring systems. Solutions involve careful tagging strategies, pre-aggregation, and specialized time-series databases.
- Centralized Log Aggregation & Analysis: Critical for correlating events across disparate services and providing a single pane of glass for debugging. Effective indexing and querying of logs are essential.
- The Value of Distributed Tracing for Pinpointing Bottlenecks: In a system with hundreds of microservices, knowing which service (or even which function call within a service) is causing latency or errors for a specific user request is almost impossible without distributed tracing. It provides the end-to-end visibility needed for performance debugging and root cause analysis.
4.4. Developer Productivity: Architecting for the Architects Themselves
The sheer complexity of a planet-scale system means that the tools and processes used by the engineering team building and operating it are just as critical as the end-user product itself. High internal developer velocity is a direct outcome of thoughtful architectural choices for the engineering workflow.
Deep Dive:
- Internal CI/CD Pipelines with High Throughput & Fast Feedback: A robust Continuous Integration/Continuous Delivery (CI/CD) pipeline is central. This involves:
- Automated Testing: Extensive unit, integration, and end-to-end tests run on every commit.
- Parallelization: Test and build jobs are highly parallelized across a massive fleet of build agents to provide rapid feedback to developers.
- Immutable Artifacts: Builds produce immutable artifacts that are consistently deployed across environments.
- Sophisticated Deployment Strategies: To minimize risk and downtime, advanced deployment strategies are employed:
- Canary Deployments: A new version is rolled out to a small subset of users or servers first, closely monitored, and then gradually expanded if healthy.
- Blue/Green Deployments: Two identical production environments run simultaneously; traffic is switched from the “blue” (old) environment to the “green” (new) one after successful testing. This provides instant rollback capability.
- Feature Flags: Allow new features to be deployed to production but toggled off by default, enabling controlled rollout to specific user segments and easy rollback without new deployments.
- Specialized Internal Tooling for Operations & Development: A highly sophisticated internal tooling ecosystem is developed to manage the complexity:
- Service Catalogues: Centralized registries of all microservices, their owners, APIs, and deployment status.
- Automated Provisioning: Tools for rapidly spinning up and tearing down infrastructure resources.
- Observability Dashboards: Custom dashboards tailored to specific services and operational roles.
- Incident Management Dashboards: Tools for tracking incident status, communication, and post-mortem analysis.
- Local Development Environment Orchestration: Tools that help developers easily spin up and manage a local, scaled-down version of the complex distributed system for development and testing.
The “Meta” Layer: This focus on internal DX (Developer Experience) creates a virtuous cycle. The architects building the platform are also users of the tools and systems that define their productivity. Architecting for seamless internal iteration, rapid feedback loops, and robust operational capabilities is as crucial as designing the user-facing features, directly impacting the platform’s ability to innovate and evolve.
5. The Fabric’s Philosophy: Engineering Principles and Future Trajectories
The journey through the architectural intricacies of a planet-scale source control and collaboration fabric reveals not just a collection of technical solutions, but a coherent engineering philosophy honed through years of operating at the bleeding edge of distributed systems. This philosophy dictates how a platform of this magnitude can not only function but continuously evolve and thrive.
Key Takeaways: Overarching Architectural Philosophies
The successful construction and sustained operation of such a complex fabric hinges on adhering to several core tenets:
- Embrace Eventual Consistency Where Appropriate, Demand Strong Consistency Where Critical: This is perhaps the most fundamental principle in hyperscale distributed systems. Architects must judiciously identify which data demands immediate, strong consistency (e.g., core metadata like permissions, pull request states) and which can tolerate temporary eventual consistency (e.g., search indices, notification streams). Attempting to enforce strong consistency universally leads to unmanageable complexity, prohibitive cost, and insurmountable performance bottlenecks. The fabric meticulously orchestrates eventual consistency through its event stream while maintaining absolute rigor for its transactional core.
- Shard Early and Often (But Judiciously): Horizontal partitioning of data and services is not merely an optimization; it’s a foundational scaling strategy. Repositories, metadata, and search indices are sharded to distribute load, improve fault isolation, and enable independent scaling. However, sharding introduces operational complexity (cross-shard queries, rebalancing) and must be implemented with careful consideration of data access patterns and growth vectors.
- API-First Internal Communication: The pervasive use of RPC services (like Gitaly) and a central distributed log (Kafka) demonstrates a commitment to API-driven, decoupled communication between services. This fosters independent development, enables robust error handling, and prevents tight coupling from hindering system evolution.
- Design for Failure: Catastrophic failures are not an “if,” but a “when.” Every component—from individual services to entire regions—is designed with redundancy, automated failover, and self-healing mechanisms. This proactive stance, reinforced by chaos engineering and rigorous testing, ensures resilience in the face of inevitable disruptions.
- Prioritize Observability as a First-Class Citizen: Telemetry (metrics, logs, traces) is not an afterthought but an integral part of system design. Deep, granular observability is the only way to understand the behavior of a complex, distributed system, diagnose issues rapidly, and ensure operational stability. You cannot fix what you cannot see.
- Automate Everything That Moves: Manual operations at this scale are unsustainable, error-prone, and a bottleneck to velocity. From infrastructure provisioning and deployments to monitoring and incident response, automation is key to managing complexity and ensuring consistent, repeatable outcomes.
Trade-offs Revisited: The Art of Compromise
A recurring theme throughout this architectural deep dive is the inherent reality that every decision involves a measured balance of performance, cost, complexity, and consistency. There is no singular “perfect” solution; rather, the “best” approach is always context-dependent, tailored to the specific problem statement, operational constraints, and business priorities.
- For instance, choosing PostgreSQL for strong metadata consistency comes with sharding complexities and the cost of distributed transactions. Opting for Kafka provides scalability and decoupling but demands idempotent consumers to handle eventual consistency. Leveraging CDNs reduces latency but introduces cache invalidation challenges.
- The architect’s craft lies not in avoiding trade-offs, but in understanding them deeply, quantifying their implications, and making informed choices that align with the platform’s long-term vision and operational realities. It is the continuous negotiation between conflicting desires that defines the resilience and efficiency of the fabric.
Future Challenges: The Evolving Horizon
Even with a robust, planet-scale architecture, the demands of the developer ecosystem are constantly evolving, presenting new challenges and exciting opportunities for architectural evolution:
- AI-Driven Code Generation and Interaction: The rise of large language models (LLMs) like GitHub Copilot introduces new architectural considerations. How will these AI agents interact with the Git fabric? Will they require new forms of API access, specialized indexing for semantic understanding, or real-time feedback loops integrated directly into the code graph? The platform may need to evolve to support millions of “AI developers” alongside human ones, with implications for concurrency, rate limiting, and ethical oversight.
- Deeper Integration with Local Developer Environments via CRDTs: While Git is distributed, the centralized hosting model still introduces some friction. Future architectures might explore wider adoption of Conflict-Free Replicated Data Types (CRDTs) to enable even more seamless, real-time, peer-to-peer collaboration directly within local IDEs, with the central fabric acting as a robust, globally consistent synchronizer rather than the sole source of truth for all interactions. This could significantly reduce latency for co-editing experiences.
- New Forms of Collaborative Code Review and Knowledge Graphing: Moving beyond traditional pull requests, future systems might incorporate richer, more dynamic collaboration models. This could involve real-time collaborative editing, semantic code navigation powered by advanced graph databases, or automated code review agents that integrate deeply into the fabric, requiring new data models and event processing paradigms.
- Serverless Git Components & Distributed Ledgers: Exploring the feasibility of pushing Git RPC functions further to the edge using serverless computing or even leveraging distributed ledger technologies for certain aspects of code provenance and immutability. This could offer new cost efficiencies and decentralization options for specific workloads.
- Environmental Sustainability at Scale: Operating at petabyte scale consumes immense energy. Future architectural decisions will increasingly weigh environmental impact, driving innovations in energy-efficient data storage, compute, and network routing.
The journey of architecting a planet-scale source control and collaboration fabric is a continuous one, characterized by relentless problem-solving and a profound understanding of distributed systems principles. For senior principal engineers and tech architects, this deep dive offers more than just a glimpse into a successful platform; it provides a critical framework for analysis.
As you design and evolve your own complex systems, consider these lessons: challenge assumptions, deeply analyze trade-offs, obsess over observability, design for resilience, and always remember that the best architecture is one that scales not just in terms of data and users, but also in terms of the velocity and well-being of the engineering teams building it. The fabric of the future awaits your blueprint.